On June 30 Anthropic shipped Claude Sonnet 5, made it the default in Claude Code, and priced it to make you look twice: $2 in and $10 out per million tokens, running through August. Opus 4.8 is $5 and $25. So the question writes itself. If the cheap new Sonnet is the default now, do you still need Opus? Mostly, no. Sonnet 5 closes the gap to within a few points on the hard benchmarks, beats Opus outright on terminal and agent work, and ties it on knowledge tasks, for roughly half the bill. Opus 4.8 keeps a real lead in the two places that still hurt: deep multi-file coding and olympiad-grade math. Here is the honest split, and when each one earns its keep.
The short answer
Sonnet 5 is the new default in Claude Code, and for good reason. It closes the gap to Opus 4.8 to a few points on the hard benchmarks, beats it outright on terminal and agent work, and ties on knowledge tasks, for 40 to 60 percent less. Opus 4.8 still wins the deepest multi-file coding and the hardest math. For most work, Sonnet 5. For the ceiling, Opus.

{kind=link}
Sonnet 5 is the new default, and that is the point
Anthropic shipped Sonnet 5 on June 30 and did something it does not usually do with a mid-tier release: made it the default model in Claude Code and on the Free and Pro plans, and called it the most agentic Sonnet yet. The phrase is marketing, but the claim under it is specific and testable. Making plans, driving a terminal or a browser without hand-holding, running a long tool loop on its own, the work that a year ago meant reaching for a flagship. Anthropic’s own framing is blunt about the target, describing it as the cheap way to run agents.
The spec sheet lines up with Opus where it counts. The context window is 1 million tokens, the same as Opus 4.8. Output tops out at 128K per response, and you can push it to 300K through a batch beta. The one thing to watch is the tokenizer: Sonnet 5 uses the newer one from the Opus 4.7 era, so the same file counts as a little more tokens than it did on Sonnet 4.6. Small on a snippet, visible on a big job.
Against its own predecessor there is no argument to have. Sonnet 5 beats Sonnet 4.6 on every published benchmark, and not by rounding error: SWE-bench Pro went from 58.1 to 63.2, Terminal-Bench from 67 to 80.4, Humanity’s Last Exam from 46.8 to 57.4. That is a real generation jump wearing a point-release number, and it is why the interesting comparison is not against the old Sonnet. It is against Opus.

{kind=link}
Where Sonnet 5 wins, and why it matters for Claude Code
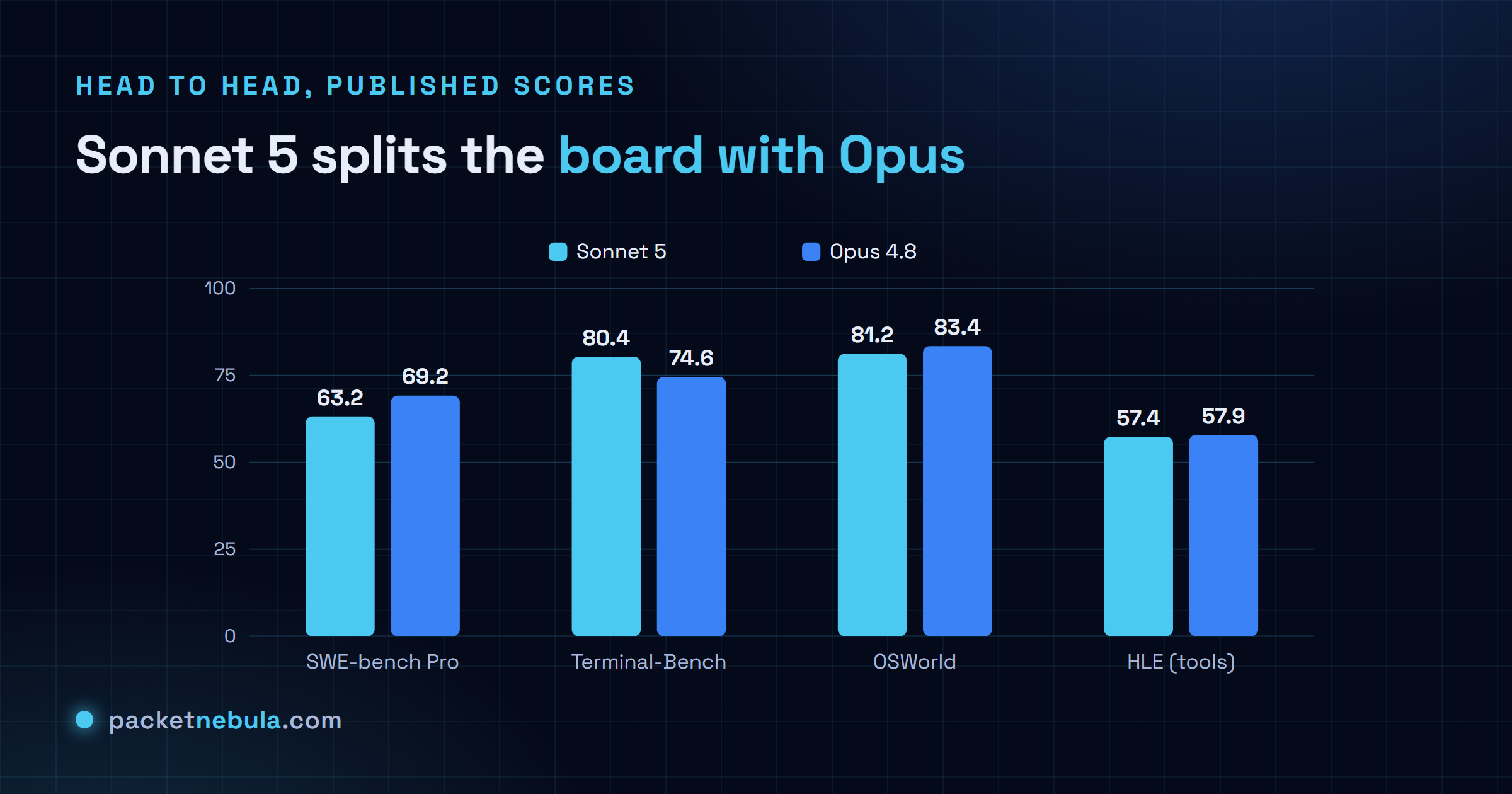
Start with the wins, because they are the reason to move. On Terminal-Bench 2.1, the benchmark for command-line and agent work, Sonnet 5 scores 80.4 to Opus 4.8’s 74.6. That is not a squeaker. It is a clear win for the cheaper model on exactly the workload Claude Code runs all day. On GDPval knowledge work it edges Opus, 1618 to 1615 on the Elo scale. On Humanity’s Last Exam with tools the two essentially tie, 57.4 to 57.9.
Put that next to the price and the case gets loud. An agent run is not one call, it is hundreds: read a file, run the tests, read the failure, patch, run again, repeat until green. Every one of those turns bills tokens, and Sonnet 5 bills 40 to 60 percent less than Opus for each. So on a task Sonnet handles at the same quality, you are paying roughly half to get the same result, and getting it faster because the smaller model returns sooner. For the median coding session, that is the entire decision, made.
The wider point is that “Sonnet-class” stopped meaning “good enough, but.” For the first time the mid-tier model wins the category its own product is built around. If your day is Claude Code driving a repo, Sonnet 5 is not the compromise pick. It is the correct one.
Where Opus 4.8 still earns its price
Now the part the launch posts skip past. Opus 4.8 keeps a real, measurable lead where the work gets deep. On SWE-bench Pro, the multi-file repository benchmark, Opus scores 69.2 to Sonnet 5’s 63.2. Six points does not sound like much until it is the difference between a refactor across a dozen files that lands clean and one that compiles but quietly breaks a caller three directories away, the kind of miss you find in production and not in review. On computer use, measured by OSWorld-Verified, Opus leads 83.4 to 81.2. On olympiad-grade math the gap is not subtle at all.
So the honest headline is not “Sonnet 5 replaced Opus.” It is narrower and more useful. Sonnet 5 replaced Opus for most of what you do, and Opus is still the model you switch to when you hit a wall. A long-horizon task that has to hold a whole system in its head, a concurrency bug that only shows up under load, a proof that needs every step right: those are still Opus jobs. The new skill is telling which task is which before you spend, rather than defaulting to the expensive model out of habit or the cheap one out of thrift.

{kind=link}
The cost story has a twist worth knowing
The price is the headline and it is genuinely good: $2 input and $10 output per million tokens through August 31, then $3 and $15. Opus 4.8 sits at $5 and $25. On rate alone Sonnet 5 is about 40 percent cheaper at standard pricing and about 60 percent cheaper during the intro window that closes at the end of August.
But rate is not the same as spend, and this is where people get surprised. Crank Sonnet 5 to maximum reasoning effort and it will happily burn more tokens to think its way to an answer, so a genuinely hard problem at xhigh effort can end up costing as much as Opus 4.8, occasionally more, for output you could not pick apart in a blind test. The savings are real and large at low and medium effort, which is where the bulk of real work sits, so the sticker usually tells the truth. At the ceiling, do the arithmetic instead of trusting it. Two levers tilt things back toward Sonnet regardless: prompt caching takes up to 90 percent off repeated context, and batch mode takes 50 percent off work that is not time-sensitive.
So which one, and how to switch
If you live in Claude Code, make Sonnet 5 your default and stop thinking about
it. In practice it already is the default, so you have it now, and the /model
command lets you pin a specific one when you want to. It is faster, it is
cheaper, and it wins the agentic tasks you run most. Keep Opus 4.8 one keystroke
away for the jobs that pay for it: a large multi-file refactor, a nasty
concurrency bug, deep math, anything where you were already scraping Sonnet’s
ceiling and need the extra six points more than you need the discount.
And if what you actually want is a model you can host yourself, or a cheaper frontier from a different lab, that is a separate shelf. Our GLM-5.2 vs GPT-5.5 vs Opus 4.8 and GPT-5.6 tier breakdowns cover the open and the OpenAI sides of the same question. Because the pattern is the same everywhere in 2026: the distance between the mid tier and the top keeps shrinking, and the money move is choosing the tier for the task, not saluting the badge.
Sources: Anthropic’s Claude Sonnet 5 announcement and the Claude Platform docs, with benchmark and pricing tables collated by MarkTechPost and The New Stack, June 30 2026. Intro pricing runs through August 31 2026; some third-party benchmark figures are as published and not yet independently reproduced.
Frequently asked questions
Is Claude Sonnet 5 better than Opus 4.8?
On most agentic and knowledge work, effectively yes, and cheaper. Sonnet 5 wins Terminal-Bench (80.4 vs 74.6), edges GDPval knowledge work, and ties Humanity's Last Exam, at 40 to 60 percent less cost. Opus 4.8 still leads deep multi-file coding (SWE-bench Pro 69.2 vs 63.2) and hard math, so it wins the hardest tasks, not the average one.
How much does Claude Sonnet 5 cost vs Opus 4.8?
Sonnet 5 is $2 input and $10 output per million tokens through August 31, 2026, then $3 and $15. Opus 4.8 is $5 and $25. So Sonnet 5 is about 60 percent cheaper during the intro window and about 40 percent cheaper after, on per-token rates.
Should I switch to Sonnet 5 in Claude Code?
For most day-to-day coding and agent runs, yes. It is the new default in Claude Code, it is faster and cheaper, and it wins terminal-style tasks. Keep Opus 4.8 on hand for large multi-file refactors and problems where you were already hitting Sonnet's ceiling.
Is Sonnet 5 always cheaper than Opus 4.8?
Not always. Per token it is, but at maximum reasoning effort Sonnet 5 can spend more tokens to reach the same answer, so a hard task at xhigh effort can cost as much as Opus 4.8 or more. The savings are clearest at low and medium effort, where most work sits.
What is the context window of Claude Sonnet 5?
One million tokens, the same as Opus 4.8, with up to 128K output tokens per response (raisable to 300K through a batch-API beta header). It uses the newer tokenizer, so the same text can count as slightly more tokens than on older Sonnet versions.