Anthropic pulled off a strange double feature. On June 30 it launched Sonnet 5 at $2 in and $10 out per million tokens, and one day later Fable 5 came back from its export-control freeze at $10 and $50. Same family, same week, same 1 million token context, and one costs exactly five times the other. So every Claude Code user now faces the same fork: the cheap default that wins agentic benchmarks, or the flagship that crushes deep coding and runs for days. The honest answer is not one model. Sonnet 5 is enough for most of what you do, Fable 5 is untouchable on the hardest tenth, and the trick is knowing which tenth. Here is the gap, priced and mapped.
The short answer
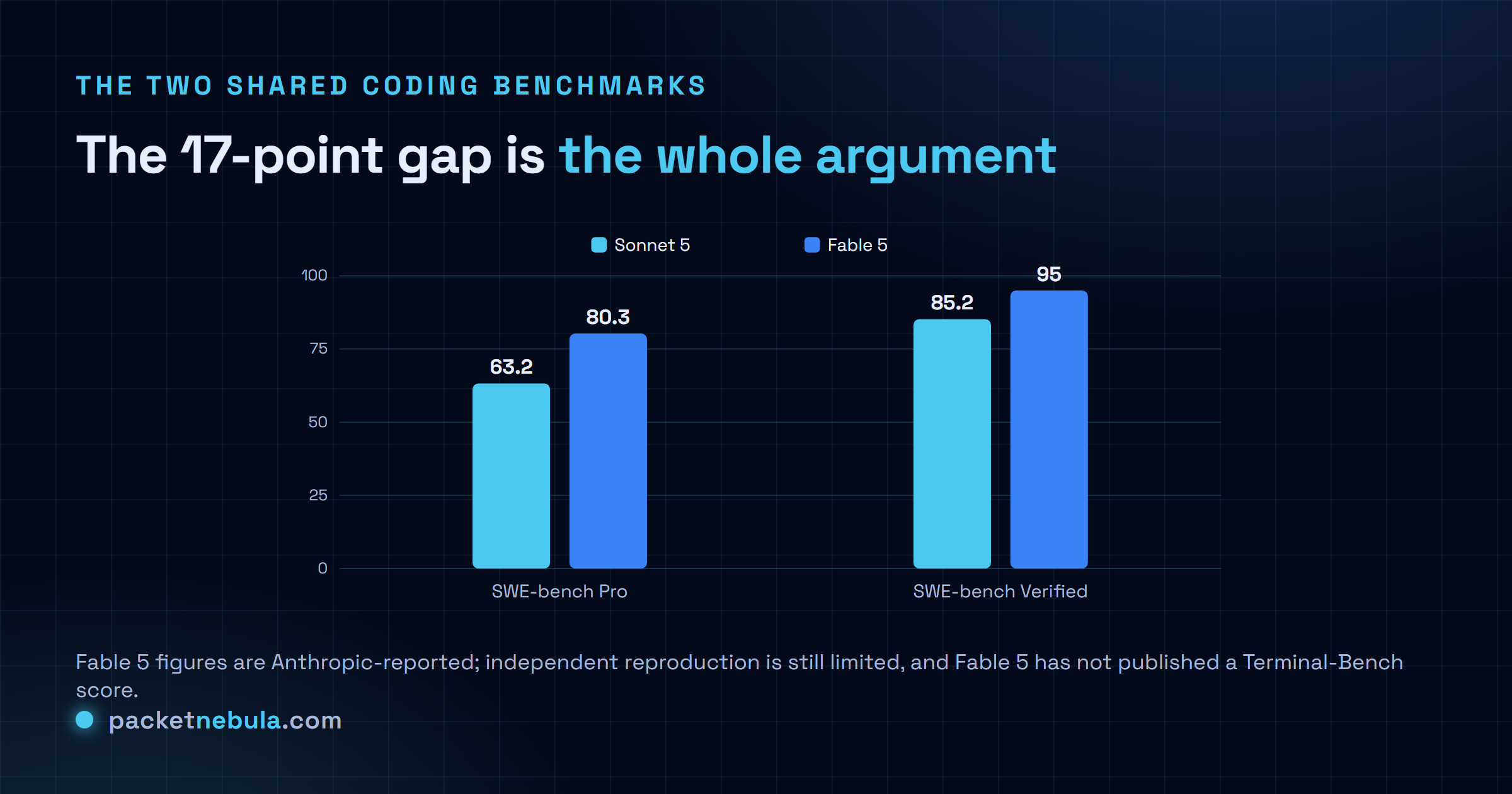
Same week, same family, five times the price. Sonnet 5 ($2/$10 intro) is the default and wins the published agentic numbers; Fable 5 ($10/$50) crushes deep coding with a 17-point SWE-bench Pro lead and runs multi-day tasks nothing else sustains. Daily driver: Sonnet 5. The hardest tenth of your work: Fable 5, deliberately, at a chosen effort level.

{kind=link}
One week, two models, one fork
The timing was almost comic. June 30: Sonnet 5 launches, becomes the default in Claude Code and on the free plans, and undercuts everything with a $2/$10 intro price that runs through August. July 1: Fable 5, Anthropic’s Mythos-class flagship, returns from nineteen days under a US export-control order at $10/$50. Two brand-new options in the same picker, twenty-four hours apart, priced exactly five times apart.
On paper they look closer than the price says. Both carry a 1 million token context window and 128K output. Both run adaptive thinking by default, both take the same effort dial up to xhigh. The spec sheet will not help you choose. The benchmarks and the bill will.
What the 5x actually buys
Start with the number that justifies Fable 5’s existence. On SWE-bench Pro, the hard multi-file repository benchmark, Fable 5 posts 80.3 against Sonnet 5’s 63.2. Seventeen points. For scale, the gap between Sonnet 5 and Opus 4.8 on the same test is six points, and we called that a real lead worth paying for on the hardest work. Fable 5 nearly triples that lead over the mid-tier. On SWE-bench Verified it is the first model past 90, at 95 against Sonnet 5’s 85.2. And on the long-horizon evals, Anthropic reports it breaking 90 percent on complex multi-step analytical work and topping Cognition’s FrontierBench, the territory of tasks that run for hours or days without a human nudging them along.
That last part is the honest heart of the pitch. Fable 5 is not a slightly smarter Sonnet. It is built for a different shape of work: the migration that touches four hundred files, the agent session that survives overnight, the research question that needs two hundred tool calls to answer properly. Sonnet 5 does not lose that work gracefully. It loses the thread, and you re-prompt, and the savings evaporate into your afternoon.

{kind=link}
What Sonnet 5 keeps anyway
Now the other side, because it is stronger than the price gap implies. Sonnet 5 holds the highest published Terminal-Bench score in the family at 80.4, ahead of Opus 4.8’s 74.6, and Fable 5’s number has simply not been published, an absence worth noticing in a launch that quoted every figure it liked. On knowledge work Sonnet 5 edges Opus on GDPval. These are the benchmarks closest to what an everyday Claude Code session actually does: drive a terminal, edit files, run tests, iterate.
There is also a verification asymmetry to keep in mind. Sonnet 5’s numbers have been picked over publicly for days; Fable 5’s headline figures are Anthropic-reported, with independent reproduction still thin and at least one benchmark conspicuously missing. None of that means the flagship is oversold. It means the exact size of the gap is provisional, and the direction is not.

{kind=link}
The bill, on the same task
Price the same turn on both rate cards and the gap stops being abstract. Take an agentic turn of 20,000 tokens in and 20,000 out. On Sonnet 5’s intro pricing it costs $0.24. On the standard pricing that starts in September, $0.36. On Fable 5, $1.20. A hundred-turn session: $24 versus $120, same work, and that assumes Fable 5 behaves. It does not always, in the sense that it always thinks, bills the thinking as output, and at xhigh effort the same turn runs closer to $3.20. Push the flagship’s dial and the daily gap is not 5x. It is 13x.
Scale it to projects and the fork gets vivid. The same 1,500-word article, five turns: about $1.20 on Sonnet 5, $6 on Fable 5. A small app, eighty turns: roughly $19 versus $96. A heavy overnight migration, three hundred turns: about $72 versus $360 and up, except that this last one is exactly the job where Sonnet 5 can lose the thread partway through, and one lost thread erases the whole saving. That is the entire decision, compressed: the cheaper model, until the task is the kind that fails expensive.
On the subscription side the asymmetry is gentler but real: Sonnet 5 is the free default everywhere, while Fable 5 rides paid plans at up to half your weekly limits through July 7 and moves to usage credits after. Either way, the flagship is metered in a way the default is not, which is exactly how Anthropic is telling you to use it.
The split that works
So run the fleet like this. Sonnet 5 is the daily driver, and since it is already the default you have to do precisely nothing: everyday coding, agent runs, drafts, reviews, the 90 percent of work where the mid-tier’s answer and the flagship’s answer are indistinguishable except on the invoice. Fable 5 is the specialist, summoned deliberately: the multi-file migration, the overnight agent, the research task with real depth, anything where Sonnet 5 already fell short once. Summon it at high effort, not xhigh, until a run proves it needs more.
And if a task sits in between, there is a middle you already know about: Opus 4.8 at $5/$25 still splits the difference on both capability and cost. The family suddenly has a real ladder again. The skill is climbing it only as far as the task demands, because the view from the top is expensive, and most days you do not need it.
Sources: Anthropic’s Sonnet 5 and Fable 5 announcements and the Claude Platform docs; benchmark tables collated by MarkTechPost and MorphLLM, June and July 2026. Fable 5 figures are largely Anthropic-reported; dollar figures are computed from published rates at equal token volumes.
Frequently asked questions
Is Claude Fable 5 better than Sonnet 5?
On raw capability, clearly: Fable 5 scores 80.3 on SWE-bench Pro against Sonnet 5's 63.2, and 95 percent on SWE-bench Verified against 85.2. It is built for long-horizon, multi-day agentic work no mid-tier model sustains. But it costs five times as much during Sonnet 5's intro pricing, so better is not the same as worth it for everyday tasks.
How much more does Fable 5 cost than Sonnet 5?
Exactly 5x during Sonnet 5's intro window: $10/$50 per million tokens versus $2/$10, through August 31, 2026. After that Sonnet 5 moves to $3/$15, making Fable 5 about 3.3x. And because Fable 5 always thinks and bills thinking as output, its real-world gap on long tasks is often wider than the rate card suggests.
Which model should I use in Claude Code?
Sonnet 5 as the default, which it already is. It wins the published terminal and agentic numbers in the family and costs a fraction of the flagship. Switch to Fable 5 for the hardest work: large multi-file migrations, tasks that run for hours or days, and problems where Sonnet 5 measurably fell short. On paid plans, Fable 5 is included up to 50 percent of weekly limits through July 7, then moves to usage credits.
Do Sonnet 5 and Fable 5 have the same context window?
Yes, both offer 1 million tokens of context with 128K max output, and both run adaptive thinking by default with the same effort levels, including xhigh. The difference is not the specs sheet, it is how far each can push a hard problem and what a token of it costs.
Are Fable 5's benchmark numbers verified?
Mostly Anthropic-reported so far, and worth reading that way. The SWE-bench Pro 80.3 and SWE-bench Verified 95 figures come from Anthropic; independent reproductions are still limited, and Fable 5's Terminal-Bench score has not been published at all. The direction of the gap is not in doubt, but treat exact deltas as provisional.