Mid-June, every AI feed we follow was yelling the same headline: the cheap open model just beat GPT-5.5. Mostly true. GLM-5.2, the open-weight model Z.ai shipped in June 2026, does beat GPT-5.5 on several coding benchmarks, and its output tokens cost roughly six times less than Claude Opus 4.8. But 'beats' and 'cheaper' hide the useful part. On the hardest long-horizon tasks Opus 4.8 still pulls clearly ahead. GLM can't see images, where Opus can. And that cheap hosted API routes through China. We've laid out the numbers, sourced and side by side, plus an honest read on when the cheap open model is the right call and when it isn't.
The short answer
GLM-5.2 from Z.ai beats GPT-5.5 on several coding benchmarks and costs about six times less than Claude Opus 4.8 on output, with open weights you can self-host for free. The catch: Opus still wins the hardest tasks clearly, and GLM can’t see images. Great value, not a clean knockout.

{kind=link}
What GLM-5.2 is, in one breath
Z.ai (the lab formerly known as Zhipu) shipped GLM-5.2 on 13 June 2026 and put the weights up a few days later. It’s a 753-billion-parameter mixture-of-experts model with only 8 experts active per token, so it punches above its raw size. Context window: 1 million tokens, with two reasoning effort levels. License: MIT, about as permissive as open weights get. One thing it doesn’t do: images. Text-only, and that matters more than it sounds.
GLM-5.2 benchmarks, minus the hype
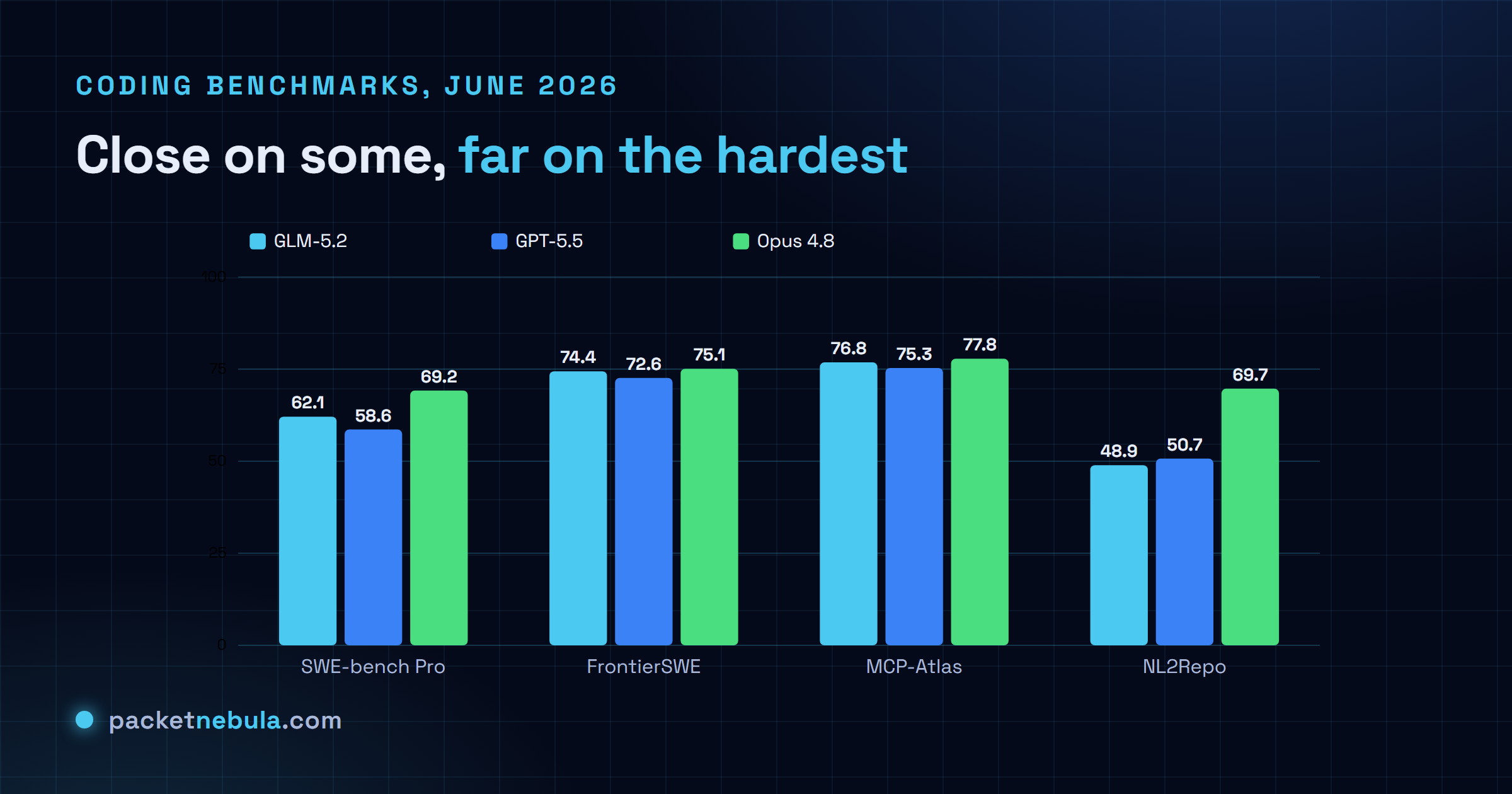
Four coding benchmarks, three models. Here’s the honest picture:

{kind=link}
The good news for the challenger is real. GLM-5.2 beats GPT-5.5 on SWE-bench Pro (62.1 to 58.6) and again on FrontierSWE (74.4 to 72.6) and MCP-Atlas (76.8 to 75.3). Against the reigning model it gets genuinely close: within 0.7 points of Opus 4.8 on FrontierSWE, within a point on MCP-Atlas. On the Code Arena frontend leaderboard it even edges Opus, #2 to Opus’s #4. For an open-weight model at a fraction of the price, that’s a serious showing.
Now the part the headlines skip. On the brutal long-horizon tests, Opus 4.8 doesn’t just win, it pulls away. NL2Repo: 69.7 against GLM’s 48.9, a 20-point gap. SWE-Marathon: 26 against 13. Double. SWE-bench Pro: a clean 7 points. Here’s the full table, copy it if you want it:
| Benchmark | GLM-5.2 | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|---|
| Terminal-Bench 2.1 | 81.0 | 84.0 | 85.0 |
| SWE-bench Pro | 62.1 | 58.6 | 69.2 |
| FrontierSWE | 74.4 | 72.6 | 75.1 |
| MCP-Atlas | 76.8 | 75.3 | 77.8 |
| NL2Repo | 48.9 | 50.7 | 69.7 |
| SWE-Marathon | 13.0 | 12.0 | 26.0 |
So “neck and neck with Opus” is true on the mid-tier and misleading as a summary. The closer the task gets to a hard multi-step problem in a real codebase, the wider Opus’s lead. Numbers from DigitalApplied and Artificial Analysis.
GLM-5.2 pricing, where it actually wins
This is the real story, not the leaderboard. Output tokens, per million:

{kind=link}
GLM-5.2 runs $1.40 in / $4.40 out per million tokens, with cached input at $0.26. Opus 4.8 is $5 / $25. GPT-5.5 is $5 / $30. So on output, where the money actually goes, GLM is roughly 5.7x cheaper than Opus and nearly 7x cheaper than GPT-5.5. On input, about 3.6x cheaper. And the weights are MIT, so you can skip the per-token bill and self-host. No closed model lets you do that. If your workload is big and the task is mid-tier, we don’t see how you argue with the math. (Anthropic and OpenAI pricing: Claude, OpenAI.)
The catches nobody puts in the headline
Three of them, and they’re not small.
It can’t see. GLM-5.2 is text-only. Opus 4.8 reads screenshots and PDFs, and pulls UI state straight out of an image. If your agent looks at a screen, GLM is out of the running. That’s a whole category of agentic work gone, today.
The cheap API has a passport. The hosted endpoint runs through a China-based provider, which is a real data-residency question if you’re sending proprietary or regulated code. The clean answer is the open weights: self-host and the question disappears. But then you’re paying for GPUs, not API calls. Do that math honestly.
It’s a June 2026 snapshot. This space turns over weekly. Today’s gap isn’t next month’s. Re-check the leaderboards before you bet a project on any of these.
So who should actually use it
Reach for GLM-5.2 when cost dominates, when you can self-host, when open weights matter for your stack, or when the work is mid-tier coding and agentic tasks that stay in text. For a lot of teams that’s most of the work. The savings are enormous.
Stay on Opus 4.8 for the hardest long-horizon coding, or for anything that touches images. Same if the last few points decide whether a multi-step agent finishes or stalls. That ceiling is what you’re paying for.
GPT-5.5 is the awkward one here. Pricier than Opus on output, behind GLM on several of these coding benchmarks, so on this particular axis it’s hard to place. It has other strengths, but “best value coder” isn’t the pitch.
Honestly, I don’t think the headline that ages best is “GLM beats GPT-5.5.” It’s that an open-weight model you can run yourself now lands a point behind the frontier on real coding work, for a fraction of the cost. That’s the thing worth watching.
Sources: VentureBeat, Artificial Analysis, DigitalApplied, plus the Anthropic and OpenAI pricing pages. Benchmarks as published in June 2026.
Frequently asked questions
Is GLM-5.2 really free?
The weights are, under an MIT license, so you can download and self-host them for nothing. The hosted API isn't free but it's cheap: about $4.40 per million output tokens. Free if you run it yourself, very low cost if you don't.
Does GLM-5.2 actually beat GPT-5.5?
On several coding benchmarks, yes. SWE-bench Pro, FrontierSWE and MCP-Atlas all put it ahead of GPT-5.5. On a couple of others, like Terminal-Bench and NL2Repo, GPT-5.5 is still in front. So it wins a lot of the long-horizon coding work, not everything.
Is it as good as Claude Opus 4.8?
Close on some tests, not on the hardest. It trails Opus 4.8 by under a point on FrontierSWE and MCP-Atlas. But Opus is far ahead on NL2Repo and SWE-Marathon, the tougher long-horizon tasks, and it's the only one of the three that can read images. So GLM runs alongside Opus on the mid-tier; it doesn't match it overall.
What is the catch with the cheap API?
Two things. It's text-only, so no image or screenshot input. And the hosted API runs through a China-based provider, which raises data-residency questions for sensitive code. Self-hosting the open weights sidesteps that one.
How much does GLM-5.2 cost?
On the hosted API it's about $1.40 per million input tokens and $4.40 per million output, with cached input near $0.26. That undercuts Claude Opus 4.8 ($5 in, $25 out) by roughly 5.7x on output, and GPT-5.5 ($5 in, $30 out) by nearly 7x. And the weights are MIT, so self-hosting drops the per-token cost to whatever your own GPUs run.
Is there a free GLM-5.2 API?
The weights are MIT-licensed, so self-hosting GLM-5.2 is genuinely free once you've got the hardware. The official hosted API is cheap but paid, around $4.40 per million output tokens. There's no official free tier; what you'll find is trial credits on model aggregators. For steady use you either self-host or pay the low hosted rate.
Will these numbers stay true?
No, and that's just the field. These are launch benchmarks from June 2026. New models and revised scores land constantly, so treat this as a snapshot and re-check the leaderboards before you bet a project on it.