Alibaba dropped Qwen 3.7 Max in May 2026, and within days the coding crowd was lining it up against GLM-5.2, the open-weight model we already pulled apart here. Good instinct, because on raw coding they are basically the same model wearing different badges: 60.6 on SWE-bench Pro for Qwen against 62.1 for GLM, MCP-Atlas inside a single point, the kind of gap that vanishes on a re-run. So the benchmark race is a draw. The real decision is everything around it. GLM is cheaper and you can self-host it; Qwen 3.7 Max is API-only but pulls ahead on math, reasoning, and agents that stay coherent for hours. Here are the numbers side by side, the price gap, and the catch nobody puts in the headline.
The short answer
On coding, Qwen 3.7 Max and GLM-5.2 are a coin flip: under 1.5 points apart on every benchmark they share. They split everywhere else. GLM is cheaper and open-weight, so you can self-host it. Qwen 3.7 Max is API-only, but it wins math and reasoning and keeps an agent coherent for far longer.

{kind=link}
What Qwen 3.7 Max actually is
Qwen 3.7 Max is Alibaba’s flagship, shipped on 21 May 2026, and it’s the closed one. Text-only, API-only, no weights to pull down (the open Qwen models are the smaller 3.6 line, like the dense Qwen3.6-27B). It carries a 1 million token context window, lands an Intelligence Index around 56.6 (fifth overall and the top-scoring Chinese model on that index), and posts the lowest hallucination rate of the current frontier at 22.9 percent.
Its real party trick is endurance. Qwen 3.7 Max can reportedly drive an autonomous agent for something like 35 hours before it loses the thread, against roughly 8 for GLM. Hold onto that number. It’s the single place these two models stop being interchangeable, and we’ll come back to it.
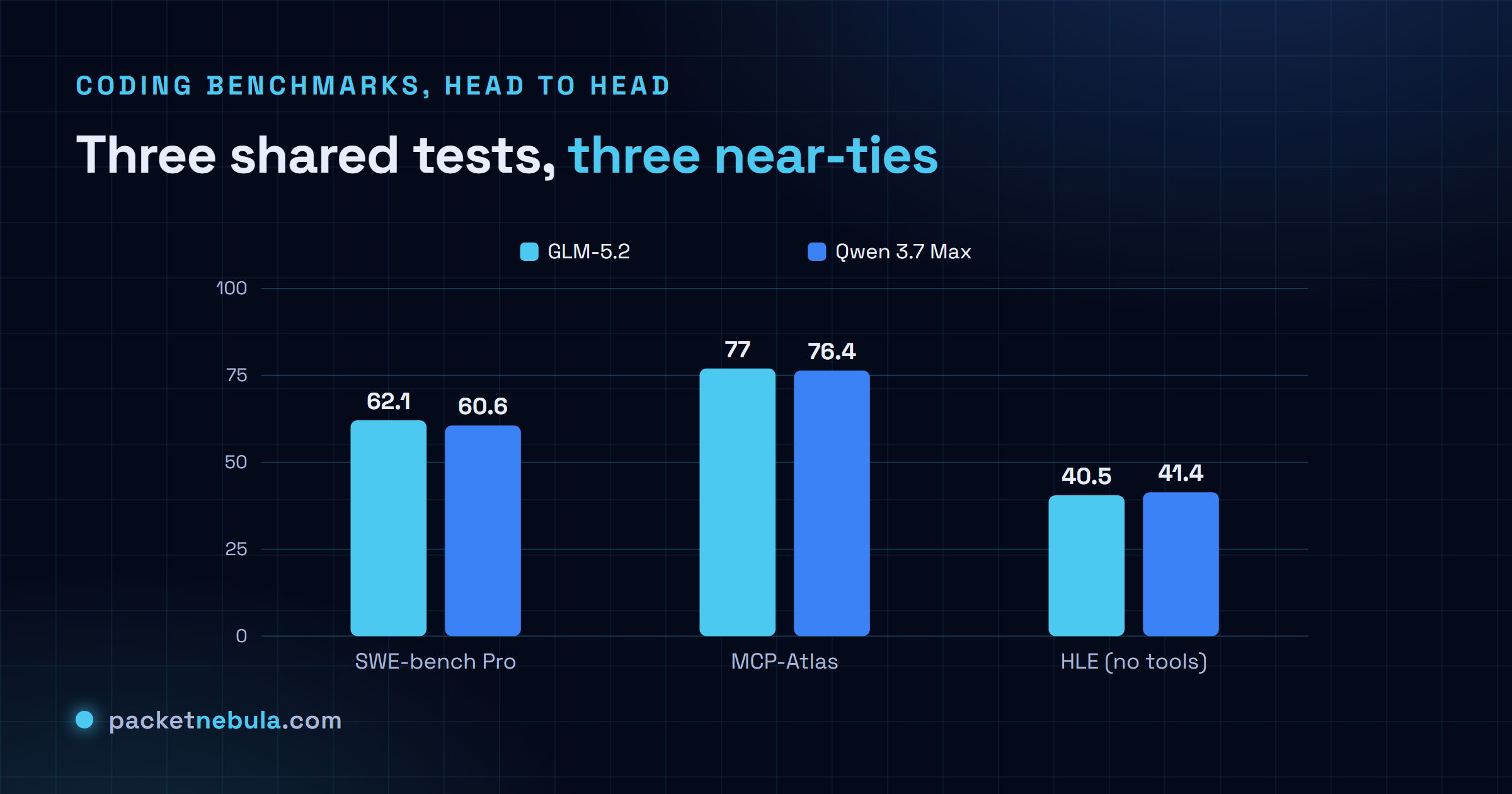
The coding race is a tie
Put them on the same coding benchmarks and you get a coin flip.

{kind=link}
SWE-bench Pro: GLM 62.1, Qwen 60.6. MCP-Atlas: 77.0 to 76.4. HLE without tools, the one Qwen takes: 41.4 to 40.5. Every gap is under a point and a half, which is inside the noise. Run the suite again next week on a slightly different harness and the winner flips. The comparison that kicked this whole thing off called the two models “twins,” and honestly that’s the right word. If your job is closing GitHub issues and shipping pull requests, you cannot pick wrong here on quality, because there’s no quality gap to pick.
Which is exactly why the benchmark table is the least useful part of this comparison. Everyone fixates on it. It decides nothing.
Where they stop being twins
Two places, and they’re both real.
First, reasoning and math, where Qwen pulls clear air. GPQA Diamond at 92.4, a near-perfect 97.1 on the HMMT competition set, 91.6 on LiveCodeBench. If your work leans on hard, multi-step reasoning rather than patching an existing codebase, Qwen 3.7 Max is the sharper instrument, and it isn’t close. GLM has its own counter (it edges ahead with tools on HLE, 54.7, and on DeepSWE at 46.2), but pure reasoning is Qwen’s room.
Second, that endurance number. A 35-hour coherent autonomous run against GLM’s eight is not a rounding difference, it’s a different category of work. For an agent that has to grind through an overnight migration or a multi-day refactor without a human nudging it back on track, Qwen holds the plot together long after GLM has wandered off. If you’re building long-running agents, this one spec probably outweighs the entire benchmark table.
GLM’s answer is narrower but it lands for a lot of teams: it’s a touch ahead on the GitHub-style coding tests, it’s cheaper, and it’s open. That last word is the one that actually moves the decision.
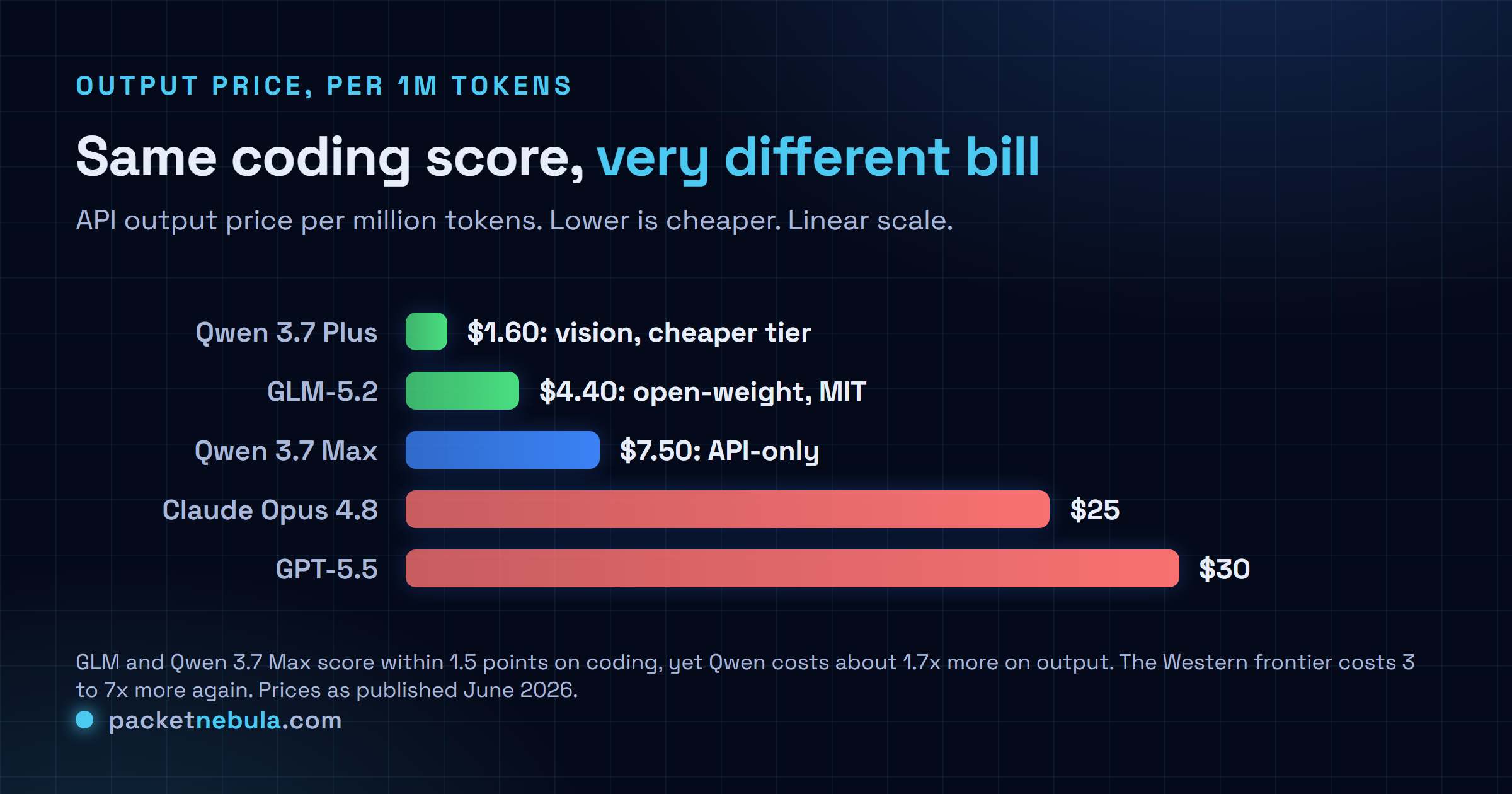
The price, and the escape hatch

{kind=link}
On output tokens, GLM runs $4.40 per million, Qwen 3.7 Max $7.50. So Qwen is about 1.7 times the bill for coding work that scores the same, which adds up at volume but won’t decide much on its own. The bigger split isn’t the number, it’s the door behind it. GLM-5.2 ships under an MIT license, so you can download the weights and run them on your own hardware, and at that point the per-token cost and the data-residency question both evaporate. Qwen 3.7 Max gives you neither. It’s API-only, and that API runs through a China-based provider, the same residency flag GLM’s hosted endpoint carries, except with GLM you have the self-host exit and with Max you don’t. If you push proprietary or regulated code through either hosted API, that one difference is close to the whole decision.
For reference, the Western frontier is still up and to the right, and still expensive. Claude Opus 4.8 leads the hardest coding, around 69 on SWE-bench Pro, a clear few points over both of these, but it charges $25 per million output, and GPT-5.5 sits at $30. Both Chinese models are landing a point or two off the frontier for somewhere between a quarter and a sixth of the price. That, not any single benchmark, is the actual story of 2026.
One more practical line: if you need to look at images, skip both. Qwen 3.7 Max is text-only and so is GLM. Qwen’s own answer there is the cheaper Qwen 3.7 Plus (June 2026, vision and video, $0.40 in and $1.60 out), and otherwise you’re back to Opus.
So which one
Reach for GLM-5.2 when cost rules, when you want to self-host, or when the work is GitHub-issue coding that stays in text. We took it apart in full in our GLM-5.2 breakdown, and it’s still the value pick of the pair.
Reach for Qwen 3.7 Max when the work is heavy on math and reasoning, or when you’re running long autonomous agents that have to stay coherent for hours, and you’re comfortable living on a hosted API with no self-host option.
Stay on Opus 4.8 for the hardest long-horizon coding and anything that touches images, when the budget allows the jump.
The headline that ages best isn’t “Qwen beats GLM,” or the reverse, because on code they don’t. It’s that two models out of Chinese labs are now trading punches a point off the frontier, one of them fully open, both at a fraction of the price. A year ago that reads like a press release. In June 2026 it’s just the leaderboard.
Sources: the GLM-5.2 vs Qwen 3.7 Max head-to-head on CodingFleet, Qwen 3.7 specs and pricing via ofox.ai and Artificial Analysis, plus our own GLM-5.2 figures. Benchmarks and prices as published in June 2026, and this field turns over fast, so re-check before you commit a project.
Frequently asked questions
Is Qwen 3.7 Max better than GLM-5.2 for coding?
On coding they are a tie. GLM-5.2 is a hair ahead on SWE-bench Pro (62.1 vs 60.6) and MCP-Atlas (77.0 vs 76.4), Qwen edges it on HLE without tools (41.4 vs 40.5), and every gap is under 1.5 points, which is inside the run-to-run noise. Pick on cost, openness or reasoning, not on the coding score.
Is Qwen 3.7 Max open-weight or open-source?
No. Qwen 3.7 Max is API-only and proprietary, with no weights to download. The open Qwen models are the smaller 3.6 line, like Qwen3.6-27B. If self-hosting matters to you, GLM-5.2 is the open one here: it ships under an MIT license.
How much does Qwen 3.7 Max cost?
About $2.50 per million input tokens and $7.50 per million output, with cached input near $0.25. That is roughly 1.7x GLM-5.2 on output ($4.40). Qwen also sells a cheaper multimodal tier, Qwen 3.7 Plus, at $0.40 in and $1.60 out.
Does Qwen 3.7 Max support images or vision?
No, Qwen 3.7 Max is text-only, and so is GLM-5.2. If you need image input, Qwen 3.7 Plus (released June 2026) adds vision and costs less, or you go to a frontier model like Claude Opus 4.8.
Qwen 3.7 Max or Claude Opus 4.8?
Opus 4.8 still leads the hardest long-horizon coding, around 69 on SWE-bench Pro against the low 60s for both Chinese models, and it reads images. But it costs $25 per million output against Qwen Max at $7.50. Opus for the ceiling and vision, Qwen Max for value plus math, reasoning and long agent runs.